
Designing MLOps Video Production Infrastructure with Avatar: An Enterprise Blueprint for India
Estimated reading time: 6 minutes
Key Takeaways
- Standardized MLOps is essential for scaling avatar-led video creation from fragile prototypes to production-grade enterprise pipelines.
- GPU Optimization and data residency are critical for Indian enterprises to comply with the DPDP Act while maintaining rendering efficiency.
- Automated Quality Gates in CI/CD pipelines, such as visual regression testing, ensure consistent output quality and brand safety.
- Strategic Integration with platforms like Studio by Truefan AI can reduce time-to-market by 65% through pre-built governance and multi-language support.
In the rapidly evolving landscape of 2026, enterprise technology leaders and ML platform teams are no longer satisfied with experimental AI video tools. They require a standardized, robust, and scalable way to build, govern, and scale avatar-led video creation that meets strict Service Level Objectives (SLOs), rigorous compliance standards, and tight cost controls. Establishing a professional MLOps video production infrastructure with avatar is now the definitive requirement for organizations looking to move from fragile prototypes to a production-grade AI video pipeline. This infrastructure represents the sophisticated application of MLOps principles to end-to-end avatar-led video generation, seamlessly combining model governance, CI/CD automation, GPU-efficient rendering, and India-specific regulatory compliance into a unified enterprise AI video pipeline.
The complexity of modern machine learning video workflows—spanning script ingestion, avatar selection, Text-to-Speech (TTS), lip-sync alignment, and high-fidelity rendering—demands a shift from "creative experimentation" to "engineering excellence." For Indian enterprises, this transition is further complicated by the operationalization of the Digital Personal Data Protection (DPDP) Act and the need for localized, high-performance GPU clusters. By the end of 2026, enterprise AI video adoption in India is projected to grow by 145%, making the implementation of production-grade AI video systems a strategic imperative rather than a technical luxury.
1. The Reference Architecture: An Enterprise MLOps Framework for Video
A successful MLOps video production infrastructure with avatar requires a fundamental rethink of traditional ML pipelines. Unlike standard tabular or NLP models, video generation involves heavy media assets, complex temporal dependencies, and multi-modal synchronization.
Data and Asset Management
In this framework, media assets are treated as first-class artifacts. This includes:
- Avatar Rigs & Voiceprints: High-fidelity digital twins and their associated acoustic models.
- Phoneme Dictionaries: Language-specific mappings required for accurate lip-sync.
- Prompt Templates: Versioned instructions for the generative models to ensure brand consistency.
- Versioning Strategy: Every asset must be versioned using semantic tagging and immutable hashes. If a brand updates its spokesperson’s avatar rig, the pipeline must ensure that older campaigns remain reproducible while new ones utilize the latest version.
The Model Stack and Registry
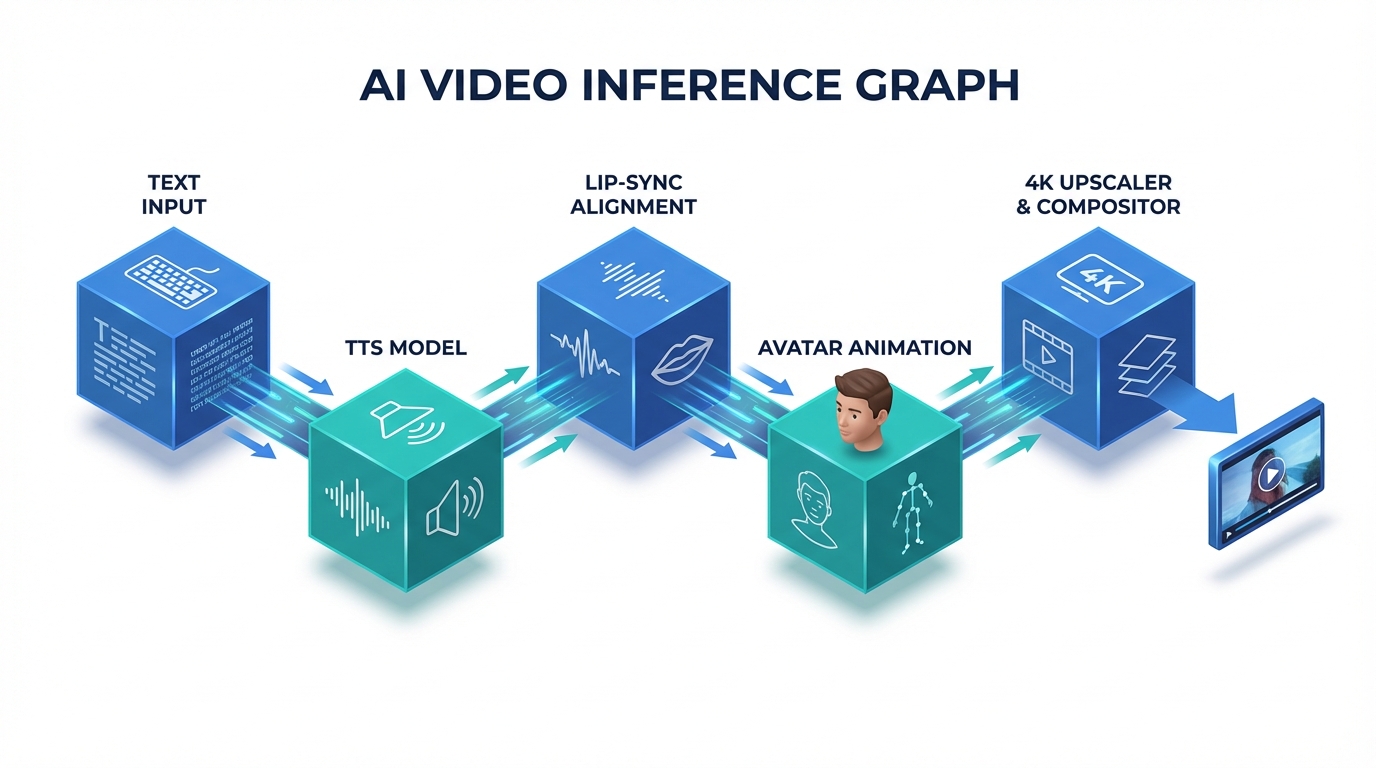
The enterprise AI video pipeline is essentially an inference graph of multiple specialized models:
- TTS Model: Converts text to natural-sounding audio.
- Lip-Sync/Alignment Model: Maps audio phonemes to facial movements.
- Avatar Animation Model: Renders the talking-head movement.
- Upscaler/Compositor: Enhances resolution and adds brand overlays.
Each of these must be registered in a model registry with metadata including training data lineage, safety evaluation scores, and cost-per-minute metrics. Promoting a model from development to production should involve automated A/B testing and shadow deployments to ensure no regression in visual quality or lip-sync accuracy.
Orchestration and Lineage
Using Kubernetes-native workflow engines like Argo or Kubeflow, enterprises can define Directed Acyclic Graphs (DAGs) that manage the entire lifecycle. For instance, an event-driven execution model decouples heavy GPU rendering jobs from the initial script validation. Platforms like Studio by Truefan AI enable enterprises to offload the complexity of avatar training and multi-language support while maintaining a stable API-first integration into their broader orchestration layer.
Source: Kubeflow vs MLFlow: Which MLOps Tool Should You Use?
2. Infrastructure & GPU Optimization: Scaling Video ML in India
Building a scalable video ML infrastructure in India requires navigating unique challenges in GPU availability, data residency, and cost management. In 2026, GPU utilization efficiency in MLOps pipelines is reaching 88% on average, but only for those who have mastered infrastructure orchestration.
Deployment Topologies and Data Residency
Under the DPDP Act 2023 and the 2025 procedural updates, Indian enterprises must ensure that personal data—including voiceprints and facial data—is processed with strict adherence to data residency requirements. A hybrid deployment model is often the most effective:
- India-Region Cloud GPUs: Used for burst rendering and localized processing to minimize latency.
- On-Prem/Private Clusters: Used for steady-state workloads and sensitive asset storage.
- VPC Endpoints: Ensuring that API calls between the orchestration layer and the rendering engine never traverse the public internet.
GPU Fleet Planning and Bin-Packing
Video rendering is notoriously resource-intensive. To optimize costs, enterprises must profile their workloads:
- Small-Batch Tasks: TTS and phoneme alignment can often run on lower-tier GPUs or even optimized CPU instances.
- Throughput-Bound Tasks: Diffusion models and 4K upscaling require high-VRAM GPUs (like NVIDIA H100s or A100s).
- Bin-Packing: Implementing intelligent scheduling that packs multiple smaller inference jobs onto a single GPU node to maximize SM (Streaming Multiprocessor) utilization.
AI Video Rendering Optimization
Optimization isn't just about hardware; it's about the software stack. Implementing mixed-precision (FP16/BF16) rendering and quantization (INT8) for TTS models can significantly reduce latency without perceptible quality loss. Furthermore, caching intermediate embeddings and static overlays (like brand logos) prevents redundant computation. Studio by Truefan AI's 175+ language support and AI avatars leverage these optimizations natively, allowing enterprises to scale without building the entire low-level rendering stack from scratch.
Source: Digital Personal Data Protection Act, 2023 - Official Text
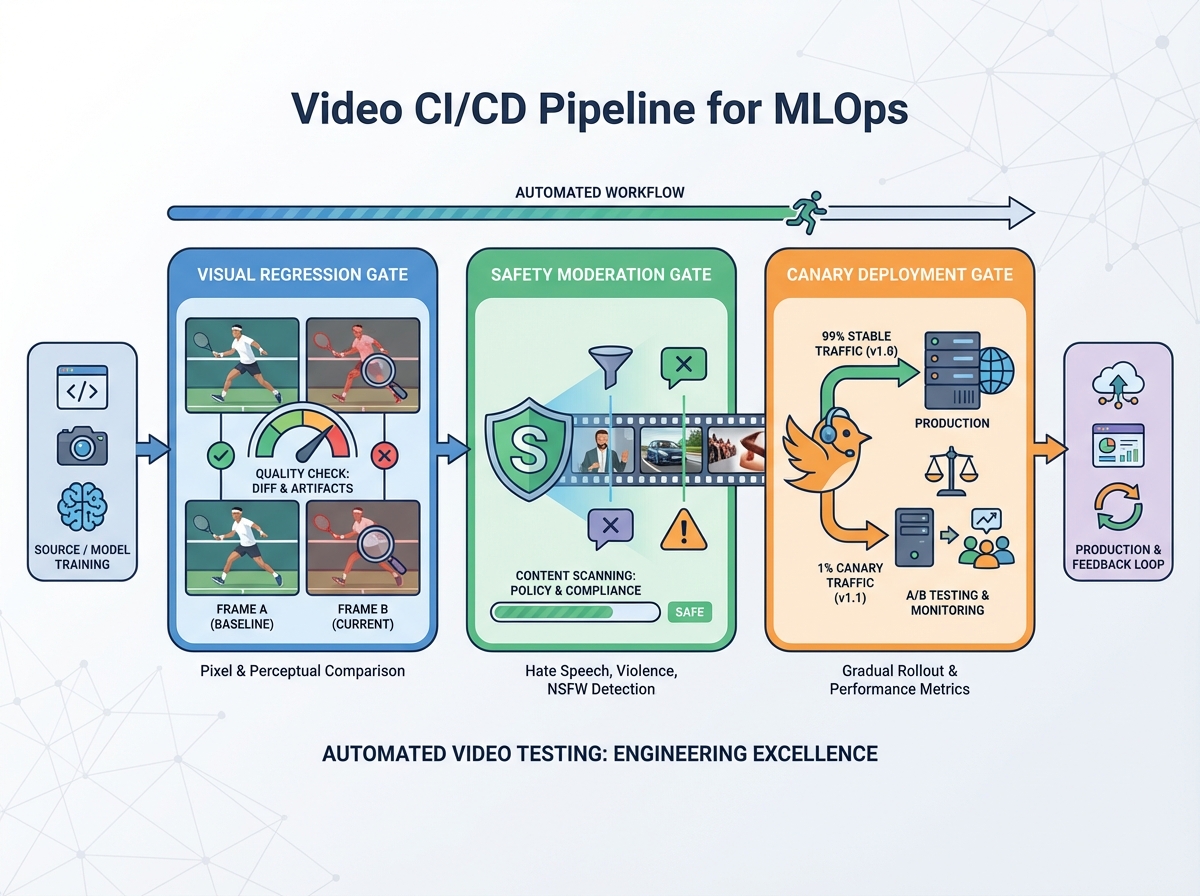
3. CI/CD and DevOps for Video Generation
A "video generation CICD pipeline" is the backbone of a production-grade system. It ensures that every change—whether to a model, a script, or a piece of infrastructure—is tested and validated before it touches production.
The CI Scope: Automated Quality Gates
Traditional CI focuses on code; Video CI focuses on the "Golden Sample."
- Unit Tests: Validating preprocessing transforms and script sanitization.
- Visual Regression Testing: Comparing a low-resolution render of a new model version against a "golden" baseline to detect artifacts or lip-sync drift.
- Safety Scans: Automatically running content through moderation models to ensure no prohibited content is generated during the build phase.
The CD Scope: Progressive Rollouts
Deploying a new avatar or a voice model should follow a canary deployment strategy. By routing 5% of render jobs to the new model and monitoring for SLO breaches (such as increased failure rates or safety score dips), teams can prevent widespread outages. Automated rollbacks are essential; if the cost-per-minute exceeds a predefined threshold or the lip-sync error rate spikes, the pipeline should revert to the previous stable version immediately.
GitOps and Infrastructure as Code (IaC)
Using tools like Terraform and Helm, the entire environment—from the Kubernetes clusters to the secret management vaults—should be defined declaratively. This ensures environment parity between development, staging, and production, reducing the "it works on my machine" syndrome that often plagues complex machine learning video workflows.
Source: Top Tools for Enabling CI/CD in ML Pipelines
4. Governance, Security, and DPDP Compliance: The 2026 Blueprint
In 2026, compliance is no longer a checkbox; it is a core architectural component. DPDP compliance costs for non-automated pipelines are estimated at $1.2M annually for large enterprises, making automated governance a financial necessity.
The DPDP-Aligned Processing Model
Enterprises must clearly define their roles as Data Fiduciaries. This involves:
- Consent Orchestration: Storing verifiable consent logs for every individual whose likeness or voice is used.
- Purpose Limitation: Ensuring that an avatar trained for "Internal Training" isn't accidentally used for "Public Marketing" without updated consent.
- Data Minimization: Automatically purging intermediate PII-derived assets (like raw voice recordings) once the final video is rendered and verified.
Authenticity and Brand Safety
To combat the rise of unauthorized deepfakes, production-grade AI video systems must implement Authenticity and Brand Safety measures:
- Cryptographic Watermarking: Embedding invisible, auditable signatures into every frame to prove provenance.
- Moderation Gates: Real-time filters that block the generation of hate speech, political endorsements, or explicit content.
- Audit Trails: Stitched into the CI/CD pipeline, providing a complete history of who generated what, when, and with which model version.
Solutions like Studio by Truefan AI demonstrate ROI through their built-in governance "walled gardens," which provide pre-licensed avatars and ISO 27001/SOC 2 certified environments, significantly reducing the compliance burden on internal platform teams.
Source: Digital Personal Data Protection Rules 2025 - Procedural Updates
5. The Operating Model: ML Engineering for Video Teams
Building an MLOps video production infrastructure with avatar requires a multi-disciplinary team. In India, where the AI talent gap in Global Capability Centres (GCCs) is projected to reach 42% by late 2026, defining clear roles is critical for success.
Roles and the RACI Matrix
- Platform Engineering: Responsible for the Kubernetes clusters, GPU scheduling, and the CI/CD backbone.
- Applied ML Engineering: Focuses on model selection, fine-tuning, and the development of evaluation metrics (e.g., lip-sync accuracy).
- Media Engineering: Handles the complexities of video codecs, frame-rate synchronization, and rendering graphs.
- Trust & Safety: Defines the moderation policies and reviews the automated safety reports.
Build vs. Integrate: Strategic Decision Making
The "Build vs. Buy" debate has shifted to "Build vs. Integrate." While an enterprise might build its own proprietary orchestration layer, it often integrates specialized platforms for the execution tier.
- When to Integrate: If you need immediate access to 175+ languages, licensed influencer avatars, and a pre-built moderation engine, integration is the faster path.
- When to Build: If you have highly specialized, proprietary rendering requirements that no commercial API can satisfy.
For most enterprises, using a robust API to connect their internal MLOps control plane to a high-performance execution backend is the most efficient route to achieving a 65% reduction in time-to-market.
Source: AI and Platform Engineering Face 42% Talent Gaps in Indian GCCs
6. KPIs, ROI, and the 90-Day Implementation Roadmap
To justify the investment in a production-grade AI video system, technical leaders must align their metrics with business outcomes. In 2026, the average ROI for avatar-led personalized video campaigns in India is hitting 4.2x, driven by increased engagement and drastically lower production costs.
Technical KPIs for the MLOps Pipeline
- Time-to-First-Frame (TTFF): Latency of the initial rendering stage.
- Render Time per Minute: The efficiency of the GPU fleet.
- Safety Pass Rate: Percentage of jobs that clear automated moderation without human intervention.
- Cost-per-minute: The total infrastructure and licensing cost of the final output.
The 90-Day Roadmap to Production
- Weeks 0–2 (Foundation): Establish the MLOps stack (Kubernetes, Registry, Observability). Define the DPDP compliance framework and select "Golden Sample" benchmarks.
- Weeks 3–6 (Pipeline): Build the Argo/Kubeflow DAGs. Integrate APIs for avatar generation and stand up the CI/CD gates.
- Weeks 7–9 (Scale): Implement GPU autoscaling and cost dashboards. Conduct "Chaos Testing" to ensure the pipeline handles burst loads.
- Weeks 10–12 (Governance): Finalize legal sign-offs, watermarking protocols, and hand over to the operational "On-Call" teams.
Conclusion
Building a professional MLOps video production infrastructure with avatar is the only way for Indian enterprises to scale their AI video ambitions safely and cost-effectively. By focusing on a robust reference architecture, optimizing GPU fleets for the local market, and embedding DPDP-compliant governance into the CI/CD process, organizations can transform video from a bottleneck into a competitive advantage. Whether you choose to build every component in-house or integrate specialized execution layers, the goal remains the same: a production-grade system that delivers high-quality, personalized content at the speed of modern business.
Frequently Asked Questions
How does the DPDP Act 2025/2026 affect the storage of voiceprints in a video pipeline?
Under the latest rules, voiceprints are considered sensitive personal data. Your MLOps infrastructure must implement data minimization, ensuring voiceprints are encrypted at rest, stored within Indian borders, and deleted once the specific purpose (rendering the video) is fulfilled, unless explicit long-term consent is obtained.
Can we use spot instances for video rendering to save costs?
Yes, but your orchestration layer must be "checkpoint-aware." Since video rendering can be long-running, use spot instances for non-urgent bulk jobs and implement logic to resume rendering from the last successful frame if an instance is preempted.
What is the primary difference between standard MLOps and MLOps for video?
The primary difference lies in "Artifact Heavy" workflows. Standard MLOps deals with small data packets; video MLOps deals with multi-gigabyte frame buffers and temporal consistency. This requires specialized high-throughput storage and media-aware CI/CD testing.
How do we ensure brand safety when using generative avatars?
Studio by Truefan AI's 175+ language support and AI avatars include built-in moderation filters that act as a "walled garden." By integrating these filters with your internal policy-as-code (like Open Policy Agent), you can ensure that no video is published without meeting both brand and regulatory safety thresholds.
What is the expected reduction in production time with an automated pipeline?
Based on 2026 industry benchmarks, enterprises moving from manual or semi-automated workflows to a full MLOps video production infrastructure see a 65% reduction in time-to-market and a 50% reduction in per-video operational costs.



