
MLOps Video Production Infrastructure 2026: Building an Enterprise AI Video Pipeline for India-Scale Workloads
Estimated reading time: 11 minutes
Key Takeaways
- Scaling to 1,000+ videos/day requires a modular, observable pipeline with idempotent retries and distributed locking to eliminate failure modes.
- DPDP 2025 compliance mandates data residency in India; deploy regionally and build governance, safety, and watermarking into the pipeline.
- Optimize GPU strategy with sharding (frame/scene) and MIG partitioning to maximize throughput and reduce cost.
- Implement video-specific CI/CD using Golden Evaluation Sets, canary rollouts, and policy-as-code to control aesthetic drift and hallucination.
- Use specialized creation layers like Studio by TrueFan AI for lip-sync, localization, and avatars to accelerate time-to-value and improve ROI.
The landscape of digital engagement has shifted from static content to dynamic, personalized video at scale. To stay competitive, Indian enterprises are now prioritizing MLOps video production infrastructure 2026 as a core pillar of their digital transformation. Building a production-grade enterprise AI video pipeline is no longer just about generating a single clip; it is about architecting a system capable of handling high-volume video infrastructure India requirements, specifically targeting 1,000+ high-quality video generations per day.
This reference architecture provides a technical roadmap for IT directors and engineering leads to build, scale, and govern an industrial-grade video ML stack that meets the unique regulatory and compute demands of the Indian market.
1. The 1,000+ Video/Day Challenge: Why Traditional Stacks Fail
Scaling video generation to 1,000+ outputs daily introduces a level of complexity that traditional image or text-based AI pipelines cannot handle. When moving toward high-volume video infrastructure India, enterprises often encounter a “reliability gap” where ad-hoc scripts and manual review processes lead to catastrophic failure modes.
The Throughput Bottleneck
Generating 1,000 videos a day—assuming an average length of 60 seconds—requires 1,000 minutes of rendered content. On a single high-end GPU, a high-fidelity video might take 5 to 10 minutes to render. Without a sophisticated enterprise video batch processing strategy, queue pileups become inevitable, leading to missed SLAs and GPU starvation.
Unique Video-ML Constraints
- Temporal Consistency: Ensuring that frames remain coherent over time requires massive memory overhead.
- Large I/O Demands: Moving tens of megabytes per second per stream necessitates high-performance storage.
- Lip-Sync Alignment: Synchronizing audio and visual layers adds a secondary inference layer that must be perfectly timed. regional language dubbing test
Platforms like Studio by TrueFan AI enable enterprises to bypass these foundational hurdles by providing a robust, API-first layer for video creation that integrates seamlessly into larger MLOps frameworks. real-time interactive AI avatars in India
The Reliability Gap in 2026
By 2026, the “agentic automation” trend is expected to reduce video render failure rates by 40%, but only for those using production-grade AI systems. Traditional stacks fail because they lack idempotent retries and distributed locking, meaning a single network flicker can result in a half-rendered, unrecoverable video file.
Source: AI Trends 2026: New Era of AI Advancements
2. Reference Architecture for an Enterprise AI Video Pipeline
To achieve “India-scale” performance, the enterprise AI video pipeline must be modular, regionalized, and highly observable. Below is the blueprint for a 2026-ready infrastructure.
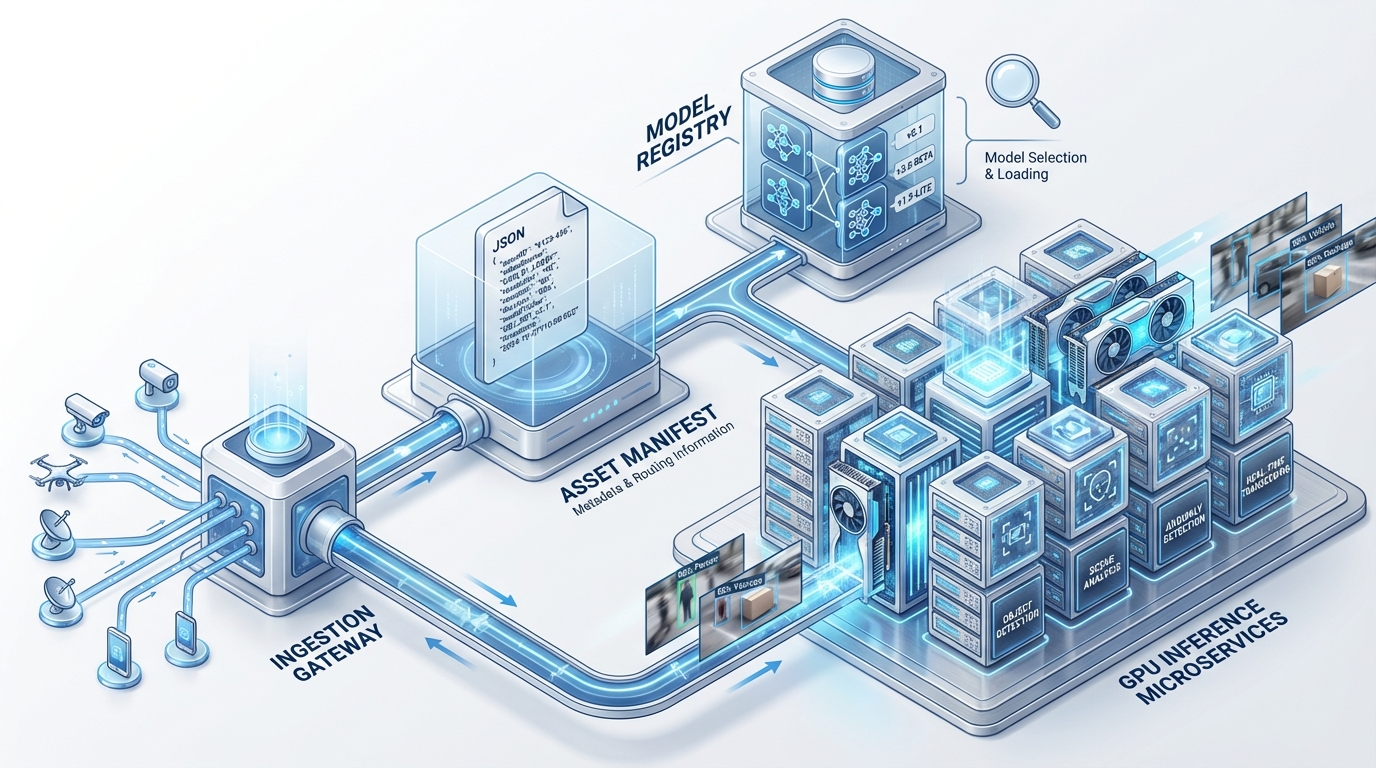
Core Components and Responsibilities
- Ingestion Gateway: This is the entry point for all video requests. It must handle schema validation and assign “idempotency keys” to every job to prevent duplicate billing or rendering.
- The Asset Manifest: Every video is defined by a JSON manifest. This record includes pointers to the source script, prompt template IDs, model weight versions (LoRA/adapters), and seed values. This ensures that any video can be perfectly reproduced for audit purposes.
- Feature Store & Model Registry: In machine learning video workflows, the feature store holds prompt features and persona metadata, while the registry versions the specific models used—such as TTS (Text-to-Speech) engines or lip-sync weights. AI voice cloning for Indian accents
- Inference Microservices: These are autoscaled containers running on GPU node pools. In a scalable video ML infrastructure India, these services are often split: one for the base video generation, one for the upscaler, and one for the safety filter.
India-Specific Deployment Patterns
With the enforcement of the DPDP (Digital Personal Data Protection) Rules 2025, data residency is non-negotiable. The architecture must be deployed within Indian regions (e.g., AWS Mumbai/Hyderabad or Google Cloud Delhi). VPC peering should be used to ensure that sensitive PII (Personally Identifiable Information) never leaves the domestic network. voice cloning with emotion control in India
Source: IndiaAI Compute Capacity and Providers
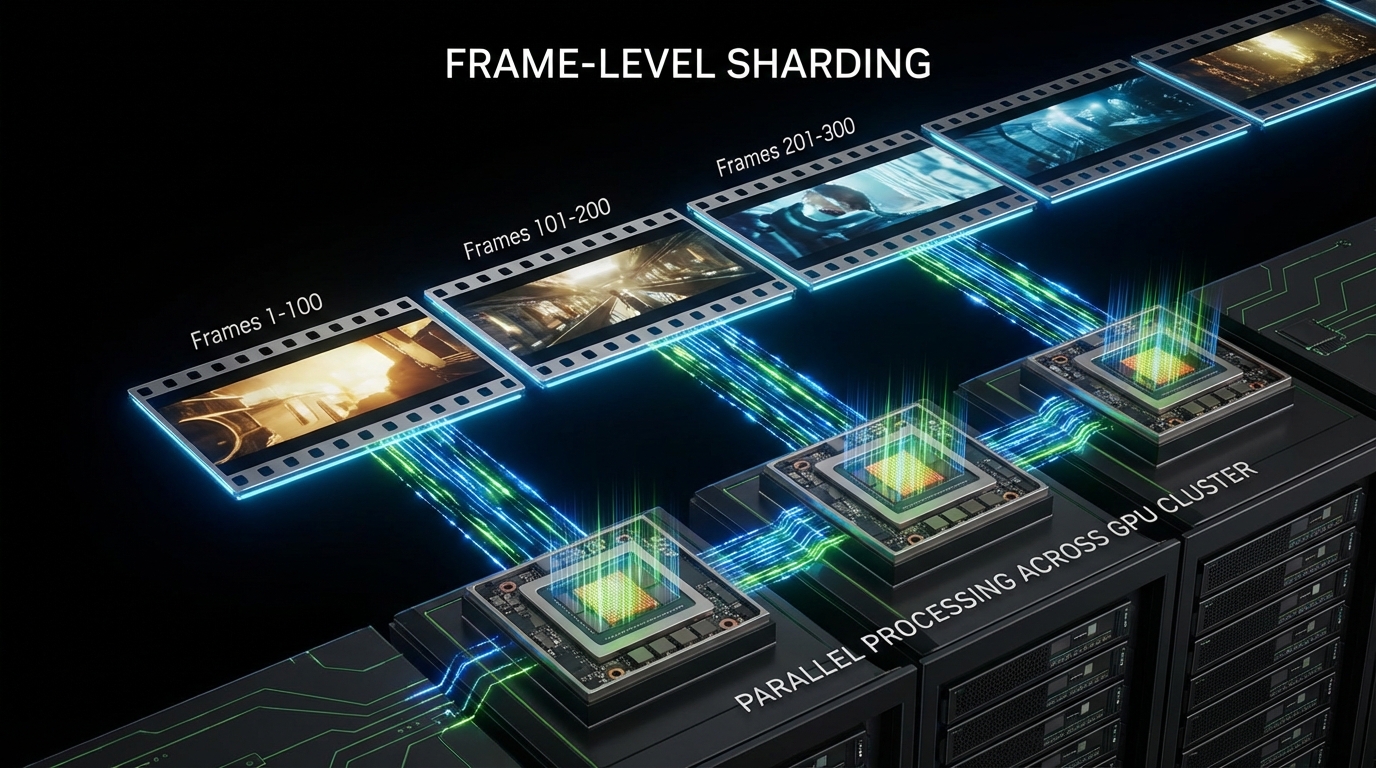
3. Parallelization and GPU Strategy: Optimizing for India’s Compute Landscape
The heart of parallel video rendering MLOps lies in how you manage your GPU resources. In 2026, the strategy has shifted from “getting any GPU” to “optimizing the specific SKU for the task.”
Sharding Strategies for Video
To hit high throughput, you cannot render a 5-minute video as a single monolithic job. You must shard:
- Frame-Level Sharding: Splitting a video into contiguous frame ranges (e.g., frames 1-100 on GPU A, 101-200 on GPU B). This requires a shared “motion vector” state to maintain temporal coherence.
- Scene-Level Sharding: Chunking by the scene graph and merging with an audio alignment post-pass.
GPU Scheduling and MIG Partitioning
Using NVIDIA’s Multi-Instance GPU (MIG) technology, enterprises can partition a single H100 into seven smaller instances. This is ideal for running lightweight TTS jobs alongside heavy diffusion-based video models, maximizing the ROI of production-grade AI systems.
The Domestic GPU Cloud Advantage
India's AI Mission has empowered domestic providers like Yotta to offer H100-scale clusters. By 2026, domestic GPU spot instance availability is projected to increase by 300%, allowing enterprises to burst their enterprise video batch processing during off-peak hours at a fraction of the cost.
Source: Yotta Empaneled in IndiaAI Mission
4. Video Generation CI/CD and DevOps Automation
A video generation CI/CD pipeline is fundamentally different from a standard software pipeline. You aren't just testing code; you are testing “aesthetic drift” and “model hallucination.”
Versioning and Gating
Every update to a prompt template or a LoRA adapter must pass through a “Golden Evaluation Set”—a collection of 50+ benchmark videos where the output is compared against a ground-truth quality score.
- Unit Tests: Validate template schema and variable injection.
- Integration Tests: Run a 5-second render to check for lip-sync accuracy. regional language dubbing test
- Canary Rollouts: Shadow-render 1% of production traffic to ensure the new model doesn't spike p95 latency.
DevOps Automation for Creation
DevOps automation video creation involves using Infrastructure-as-Code (Terraform/Pulumi) to manage GPU node pools. In 2026, “Policy-as-Code” (using OPA/Rego) is used to enforce watermarking. If a render job does not include a machine-detectable watermark, the pipeline automatically kills the process to ensure compliance. voice cloning with emotion control in India
Source: Kubeflow vs MLflow: Which MLOps Tool to Use?
5. Governance, DPDP Compliance, and Safety in 2026
Operating a scalable video ML infrastructure India requires strict adherence to the DPDP Rules 2025. Enterprises are now classified as “Significant Data Fiduciaries” if they process high volumes of personal data for video personalization.
Data Residency and Cross-Border Rules
All personal data—including the faces and voices used for AI avatars—must remain within India. If a global enterprise needs to transfer data, they must apply the specific safeguards outlined in the 2025 rules, including SCC-like contracts and mandatory Data Protection Impact Assessments (DPIAs).
The 2026 Safety Pipeline
- Pre-Gen: Linting prompts for restricted keywords (political, hate speech).
- In-Gen: Classifier hooks that monitor the latent space for “not-safe-for-work” (NSFW) patterns.
- Post-Gen: AI-based content filters and mandatory watermarking. voice cloning with emotion control in India
By Q1 2026, DPDP compliance audits are expected to consume up to 15% of an enterprise's AI IT budget, making built-in governance a critical feature for any platform.
Source: First Read on the DPDP Rules 2025
6. Throughput Economics: Cost Math for High-Volume Video Infrastructure
To justify the investment in MLOps video production infrastructure 2026, IT leaders must master the unit economics of AI video.
The Cost-Per-Minute Formula
The total cost of a rendered minute is not just the GPU hourly rate. It must include:
Cost per Minute = [(GPU_Hour_Rate / 60) / Utilization_Factor] + Storage_Overhead + Moderation_API_Costs
In the Indian market, the average cost per AI-generated video minute is projected to drop to ₹45 by Q3 2026, provided the infrastructure maintains a utilization factor of at least 0.75.
GPU SKU Comparison (Projected 2026 Rates)
| GPU SKU | Hourly Rate (INR) | Throughput (Videos/Hr) | Cost Per Video (60s) |
|---|---|---|---|
| NVIDIA H100 | ₹450 | 12 | ₹37.50 |
| NVIDIA L40S | ₹280 | 7 | ₹40.00 |
| A100 (Legacy) | ₹180 | 4 | ₹45.00 |
Solutions like Studio by TrueFan AI demonstrate ROI through optimized inference engines that maximize these throughput numbers, often delivering a 30% lower TCO (Total Cost of Ownership) than custom-built, unoptimized stacks. best AI voice cloning software
Source: H100 Price in India: Cost Modeling
7. Implementation Roadmap and the Role of Studio by TrueFan AI
Building a full-scale enterprise AI video pipeline is a multi-month journey.
- Phase 0 (30 Days): Pilot a single-region pipeline in India. Establish a model registry and manual QA gates.
- Phase 1 (60-90 Days): Implement enterprise video batch processing with idempotent DAGs and initial FinOps dashboards.
- Phase 2 (90-150 Days): Introduce parallel video rendering MLOps (frame sharding) and automated safety checks.
- Phase 3 (150+ Days): Achieve a steady state of 1,000+ videos/day with multi-region high availability.
Where Studio by TrueFan AI Fits
For enterprises looking to accelerate this roadmap, Studio by TrueFan AI serves as the “last-mile” creation layer. Studio by TrueFan AI's 175+ language support and AI avatars allow technical teams to focus on the infrastructure while the platform handles the complexities of lip-sync, localization, and avatar realism. real-time interactive AI avatars in India
By integrating Studio’s APIs into your orchestration layer (like Airflow or Kubeflow), you can trigger high-volume jobs, retrieve status via webhooks, and ensure all outputs meet the highest standards of enterprise governance.
Conclusion
As we move through 2026, the ability to generate 1,000+ videos daily will become a standard requirement for Indian enterprises. By investing in a robust MLOps video production infrastructure 2026, focusing on domestic GPU resources, and leveraging specialized platforms for the creation layer, organizations can turn video from a bottleneck into a competitive advantage.
Ready to blueprint your infrastructure? Request a 2026 MLOps video production infrastructure assessment and join our enterprise architecture workshop.
Frequently Asked Questions
How does DPDP 2025 affect AI video generation in India?
The DPDP Rules 2025 mandate that all personal data used for training or inference—such as a customer's name or face for a personalized video—must be stored and processed within India. It also requires “Significant Data Fiduciaries” to conduct regular audits and appoint a Data Protection Officer (DPO).
What is the difference between frame-level and scene-level sharding?
Frame-level sharding splits a single continuous shot across multiple GPUs, which is faster but requires complex synchronization to avoid “flicker.” Scene-level sharding splits the video by cuts or transitions, which is easier to implement but may result in uneven GPU utilization if one scene is significantly longer than others.
Can I use spot instances for high-volume video infrastructure?
Yes, but your video generation CI/CD pipeline must be “preemption-aware.” This means the system must save intermediate render artifacts (checkpoints) so that if a GPU is reclaimed, the job can resume from the last saved frame rather than starting over.
How do I ensure my AI videos are not used for deepfakes?
Implementing a “Defense-in-Depth” strategy is key. Platforms like Studio by TrueFan AI enable secure video generation by using built-in content filters, mandatory digital watermarking, and consent-based avatar modeling. This ensures that every video produced is traceable and adheres to ethical AI standards.
What is an “Asset Manifest” in MLOps?
An asset manifest is a version-controlled JSON file that contains every parameter used to create a video. This includes the model hash, the prompt, the seed, the temperature, and the specific version of the TTS engine. It is the “source of truth” for reproducing any AI asset.
Why is p95 latency more important than average latency in video production?
In high-volume environments, average latency can hide “tail end” failures. If 95% of your videos (p95) take 6 minutes to render but 5% take 60 minutes due to queue congestion, your entire campaign delivery is at risk. Monitoring p95 ensures your infrastructure is scaled for the worst-case scenario.


